
1. 1. 이클립스 설치와 프로젝트 불러오기
1.1. 이클립스 설치
자바 애플리케이션을 동작하기 위한 이클립스 IDE를 설치하자.
2020-06 R | Eclipse Packages
444 MB 4,652 DOWNLOADS The Modeling package provides tools and runtimes for building model-based applications. You can use it to graphically design domain models, to leverage those models at design time by creating and editing dynamic instances, to collabo
www.eclipse.org
1.2. 예제 프로젝트 불러오기
이클립스에서 예제 프로젝트를 불러오자.
GitHub - holyeye/jpabook
Contribute to holyeye/jpabook development by creating an account on GitHub.
github.com
설치한 이클립스를 실행 후 File > Import 에서

Maven > Existing Maven Projects에서 다음 메이븐 프로젝트를 불러온다.
이 화면에서 Browse 버튼을 눌러 예제가 있는 경로 선택 후 Finish 버튼을 선택하여 모든 예제 프로젝트를 불러오자.
처음 시작할 프로젝트는 ch02-jpa-start1이다.
*주의 예제를 실행하려면 Maven이 설치 되어야함. 요즘 이클립스는 메이븐이 내장되어 있음
1.3. 메이븐 오류 해결
메이븐 관련 오류가 발생하면 프로젝트에서 오른쪽 마우스 클릭후 Maven > Update Project 선택 후 문제가 발생한 메이븐 프로젝트를 초기화하고 다시 환경을 구성한다. 문제가 해결되지 않으면 이 과정을 2~3번 반복한다. 만약 그래도 해결되지 않으면 이 밑의 화면에서
Force Update~ 를 체크 후 진행.
2. 2. H2 DB 설치
MySQL이나 Oracle DB설치해도 괜찮지만 예제이기 때문에 가벼운 H2 DB를 사용하겠다. 참고로 H2 DB는 자바가 설치되어야 동작한다.
2.1. H2 DB설치 방법
H2 Database Engine
H2 Database Engine Welcome to H2, the Java SQL database. The main features of H2 are: Very fast, open source, JDBC API Embedded and server modes; in-memory databases Browser based Console application Small footprint: around 2.5 MB jar file size Supp
www.h2database.com
All Platforms 설치한다. 참고로 예제에서 사용한 버전은 1.4.187이고 다른 버전을 사용하면 정상 동작하지 않을 수 있다. 그럴 경우 다음 경로를 통해 내려받자.
Archive Downloads
www.h2database.com
압축을 푼 곳에서 bin/h2.sh를 실행하면 H2 DB를 서버 모드로 실행한다.(윈도우는 h2.bat 또는 h2w.bat을 실행)
&H2 DB에서는 JVM메모리 안에서 실행되는 임베디드 모드와 실제 DB처럼 별도의 서버를 띄워서 동작하는 서버 모드가 있다.
*H2 DB에서는 JVM 메모리 안에서 실행되는 임베디드 모드와 실제 DB에서처럼 별도의 서버를 띄워서 동작하는 서버 모드가 있다.
H2 DB를 서버 모드로 실행한 후에 웹 브라우저에서 http://localhost:8082 입력하면

이렇게 나오게 되고 한국어 선택 후

다음과 같이 입력후 연결을 클릭한다.
이렇게 하면 test라는 이름의 DB에 서버 모드로 접근하고
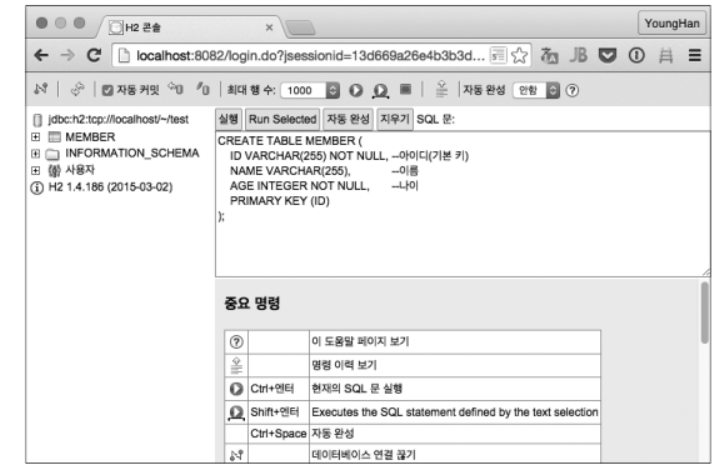
다음과 같은 화면이 완성된다. 위와 같은 SQL입력하고 실행 버튼을 선택하면 MEMBER 테이블을 확인할 수 있다.
3. 3. 라이브러리와 프로젝트 구조
필요한 모든 라이브러리를 직접 내려받아서 관리하기는 어려우므로 메이븐이라는 도구를 활용 메이븐은 간단히 말해 라이브러리를 관리해주는 도구인데 pom.xml에 사용할 라이브러리를 적어주면 라이브러리를 자동으로 내려받아서 관리해준다.

3.1. 메이븐(Maven)기능
- 라이브러리 관리 기능 : 과거에는 라이브러리를 직접 내려받아서 사용, 현재는 라이브러리 이름과 버전만 명시하면 라이브러리를 자동으로 내려받고 관리해줌
- 빌드 기능 : 과거에는 Ant를 주로 사용, 현재는 Maven이 애플리케이션을 빌드하는 표준화된 방법을 제공
JPA 구현체로 하이버네이트를 사용한다.
- hibernate-core : 하이버네이트 라이브러리
- hibernate-entitymanager : 하이버네이트가 JPA 구현체로 동작하도록 JPA 표준을 구현한 라이브러리
- hibernate-jpa-2.1-api : JPA 2.1 표준 API를 모아둔 라이브러리
다음은 pom.xml을 살펴보자.

JPA에 하이버네이트 구현체를 사용하려면 많은 라이브러리가 필요하지만 핵심 라이브러리는 다음 2가지이다.
- JPA, 하이버네이트(hibernate-entitymanager) : JPA 표준과 하이버네이트를 포함하는 라이브러리, hibernate-entitymanager를 라이브러리로 지정하면 hibernate-core.jar, hibernate-jpa-2.1-api.jar 두 라이브러리도 함께 내려받는다.
- H2 DB : H2 DB에 접속해야 하므로 지정
4. 4. 객체 매핑 시작
4.1. 1. SQL 을 실행하여 회원 테이블 생성

4.2. 2. 회원 클래스 생성


JPA를 사용하려면 가장 먼저 회원 클래스와 회원 테이블을 매핑해야한다.
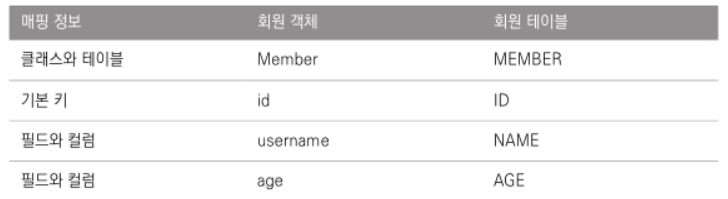
그러려면 회원 클래스에 JPA가 제공하는 매핑 어노테이션을 추가하자.
4.3. 3. 매핑 어노테이션 추가


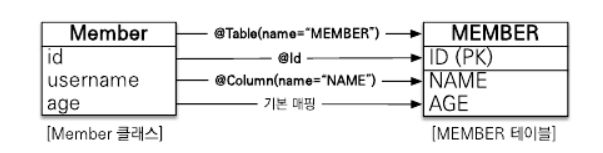
- @Entity
엔티티 클래스에 매핑할 테이블 정보를 알려준다. 여기서는 name 속성을 사용하여 Member 엔티티를 MEMBER테이블에 매핑함. 이 어노테이션을 생략하면 클래스 이름을 테이블 이름으로 매핑한다.
- @Id
엔티티 클래스의 필드를 테이블의 기본 키 에 매핑한다. 여기서는 엔티티의 id 필드를 테이블의 ID 기본 키 컬럼에 매핑. 이렇게 @Id가 사용된 필드를 식별자 필드라 한다.
- @Column
필드를 컬럼에 매핑한다. 여기서 name 속성을 사용하여 Member 엔티티의 username 필드를 MEMBER 테이블의 NAME 컬럼에 매핑했다.
4.4. 매핑 정보가 없는 필드
age 필드에는 매핑 어노테이션이 없다. 이렇게 매핑 어노테이션을 생략하면 필드명을 사용해서 컬럼명으로 매핑한다. 여기서는 필드명이 age 이므로 age 컬럼으로 매핑했다. 여기서는 DB가 대소문자를 구분하지 않으니까 가능하다. 하지만 대소문자를 구분하는 DB를 사용하면 @Column(name = "AGE") 로 명시해야 한다.
다음은 JPA를 실행하기 위한 기본 설정 파일인 persistence.xml을 알아보자.
5. 5. persistence.xml 설정
JPA는 persistence.xml을 사용하여 필요한 설정 정보를 관리한다. 이 설정 파일이 META-INF/persistence.xml 클래스 패스 경로에 있으면 별도의 설정 없이 JPA가 인식할 수 있다.


5.1. Persistence.xml 상세히 알아보기

설정 파일은 persistence로 시작한다. 이곳에 XML 네임스페이스(하나밖에 없는 특별한 주소)와 버전을 지정한다. JPA 2.1 버전을 사용하려면 이 xmlns와 version을 명시하면 된다.

JPA 설정은 영속성 유닛(persistence-unit)이라는 것부터 시작하는데 일반적으로 연결할 DB당 하나의 영속성 유닛을 등록하고, 영속성 유닛은 고유한 이름을 부여해야 함. 여기서는 jpabook이라는 이름을 사용

- JPA 표준 속성
- javax.persistence.jdbc.driver : JDBC 드라이버
- javax.persistence.jdbc.user : DB 접속 아이디
- javax.persistence.jdbc.password : DB 접속 비밀번호
- javax.persistence.jdbc.url : DB 접속 URL - 하이버네이트 속성
- hibernate.dialect : DB 방언(Dialect) 설정
dialect 속성과 관련하여 더 궁금한 점은 아래에 더 상세히 설명드리겠습니다.
5.2. 데이터베이스 방언(Dialect)
JPA는 특정 DB에 종속적이지 않은 기술이므로 다른 DB로 손쉽게 교체 가능하지만 각 DB가 제공하는 SQL 문법과 함수가 조금씩 다르다는 문제점이 있다.
데이터 타입 : (가변 문자타입) MySQL은 VARCHAR , 오라클은 VARCHAR2
다른 함수명 : (문자열을 자르는 함수) SQL 표준은 SUBSTRING(), 오라클은 SUBSTR()
페이징 처리 : MySQL은 LIMIT, 오라클은 ROWNUM
이처럼 특정 DB만의 고유 기능을 JPA에서는 방언 이라고 한다. 하이버네이트를 포함한 대부분의 JPA 구현체들은 이런 문제를 해결하기 위해 다양한 DB 방언 클래스를 제공한다. 따라서 DB가 변경되어도 코드를 변경하지 않고 방언만 교체해주면 된다.
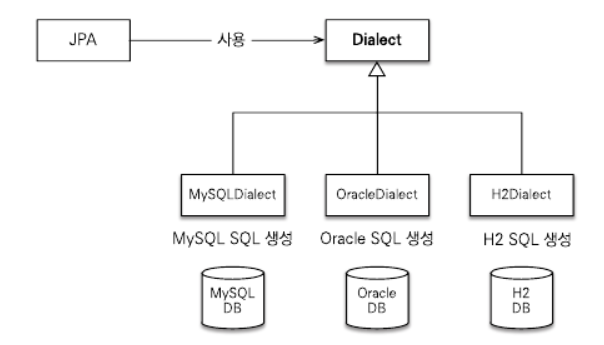
- DB방언 교체 방법
- H2 : org.hibernate.dialect.H2Dialect
- 오라클 10g : org.hibernate.dialect.Oracle10gDialect
- MySQL : org.hibernate.dialect.MySQL5InnoDBDialect
여기서는 H2 DB를 사용하므로 org.hibernate.dialect.H2Dialect로 설정
6. 6. 애플리케이션 개발
객체 매핑 완료 후 persistence.xml로 JPA 설정도 완료하였다. 이제 JPA 애플리케이션을 개발해보자.


코드는 3부분으로 나뉘어 있다.
- 엔티티 매니저 설정
- 트랜잭션 관리
- 비즈니스 로직
6.1. 엔티티 매니저 설정
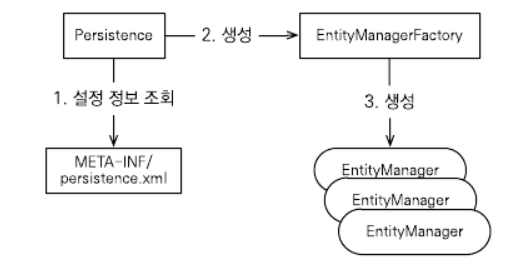
- 엔티티 매니저 팩토리 생성
JPA를 시작하려면 우선 persistence.xml의 설정을 사용하여 엔티티 매니저 팩토리를 생성해야 한다. 이때 Persistence 클래스를 사용하는데 이 클래스는 엔티티 매니저 팩토리를 생성해서 JPA를 사용할 수 있게 준비한다.
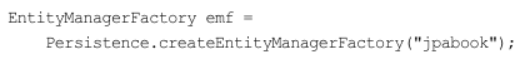
이렇게 하면 META-INF/persistence.xml에서 이름이 jpabook인 영속성 유닛을 찾아서 엔티티 매니저 팩토리를 생성한다.
- 이때 persistence.xml의 설정 정보를 읽음
- JPA를 동작시키기 위한 기반 객체를 만듦
- JPA 구현체에 따라서는 DB와 커넥션 풀도 생성
- 엔티티 매니저 팩토리를 생성하는 비용 매우큼(그러므로 팩토리는 딱 한번만 생성, 공유
- 엔티티 매니저 생성
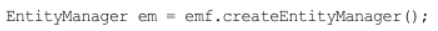
엔티티 매니저 팩토리에서 엔티티 매니저를 생성. JPA 기능 대부분은 이 엔티티 매니저가 제공한다.
대표적으로 엔티티 매니저를 사용하여 DB에 CRUD할 수 있다. 개발자는 엔티티 매니저를 가상의 DB로 생각할 수 있다.
+ 엔티티 매니저는 DB 커넥션과 밀접한 관계가 있으므로 스레드간에 공유하거나 재사용 금지
- 종료
사용이 끝난 엔티티 매니저와, 매니저 팩토리를 종료
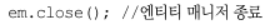

6.2. 트랜잭션 관리
JPA를 사용하면 항상 트랜잭션 안에서 DB를 변경해야 한다(트랜잭션 없이 변경하면 예외가 발생). 트랜잭션을 시작하려면 엔티티 매니저(em)에서 트랜잭션 API를 받아와 사용

트랜잭션 API를 사용하여 비즈니스 로직이 정상이면 commit하고 실패하면 rollback한다.
6.3. 비즈니스 로직

출력 결과

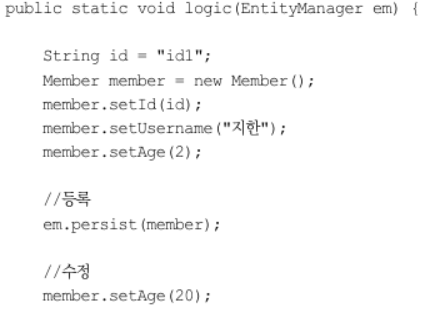
- 등록
JPA는 회원 엔티티의 매핑 정보(어노테이션)를 분석해서 다음과 같은 SQL을 만들어 DB에 전달한다.
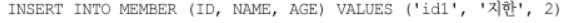
- 수정
JPA는 어떤 엔티티가 변경되었는지 추적하는 기능을 갖추고 있다.
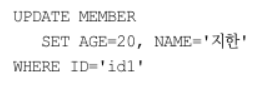
- 삭제
JPA는 다음 DELETE SQL을 생성, 실행한다.
- 한 건 조회
find() 메서드는 조회할 엔티티 타입과 @Id로 DB 테이블의 기본 키와 매핑한 식별자 값으로 엔티티 하나를 조회하는 가장 단순한 조회 메서드다. 이 메서드를 호출하면 다음 SELECT SQL을 생성하여 DB에 결과를 조회한다. 그리고 조회한 결과 값으로 엔티티를 생성해서 반환한다.

6.4. JPQL
하나 이상의 목록을 조회하는 코드를 살펴보자.

JPA를 사용하면 개발자는 엔티티 객체를 중심으로 개발해야 한다. JPA를 사용하여 검색을 할때도 마찬가지로 테이블이 아닌 엔티티 객체를 대상으로 검색해야 한다. 그런데 테이블이 아닌 엔티티 객체를 대상으로 검색하려면 DB의 모든 데이터를 애플리케이션으로 불러와서 엔티티 객체로 변경한 다음 검색해야 하는데, 이는 사실상 불가능하다. 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL을 사용해야 한다. JPA는 JPQL (Java Persistence Query Language)라는 쿼리 언어로 해결한다.
JPQL은 SQL과 문법이 거의 유사하다.
- SQL과 JPQL의 차이점
- JPQL은 엔티티 객체를 대상으로 쿼리한다. 쉽게 말해 클래스와 필드를 대상으로 한다.
- SQL은 DB 테이블 대상으로 쿼리한다.
여기서 from Member는 회원 엔티티 객체를 말함 (MEMBER 테이블이 아니다).
JPQL은 DB 테이블을 전혀 알지 못한다.
JPA는 JPQL을 분석해서 다음과 같은 SQL을 만들어 DB에서 데이터를 조회한다.

'Spring > JPA' 카테고리의 다른 글
| 엔티티 매핑 (0) | 2023.07.11 |
|---|---|
| 영속성 관리 (0) | 2023.07.10 |
| JPA란 무엇인가? (0) | 2023.07.09 |
| JPA 패러다임의 불일치 (0) | 2023.07.09 |
| JPA 소개 (0) | 2023.07.07 |
